When does context rot happen?
Dec 7, 2025
Context Rot Guide from Chroma Research*
How Increasing Input Tokens Impacts LLM Performance
1. Background & Key Findings
Why This Research
Problem: NIAH (Needle in a Haystack) is the standard benchmark for long-context LLM performance
Hides info in long documents, asks model to find it
Most models score near-perfect → "long-context is solved" belief
But NIAH only tests lexical matching (question and answer share keywords)
Doesn't test semantic inference
Doesn't test filtering similar-but-wrong info
Doesn't test finding blended information
NoLiMa dataset: 72.4% of needle-question pairs require external/semantic knowledge beyond simple keyword matching
So Chroma tested 18 LLMs on realistic tasks → discovered Context Rot
Context Rot
Performance degrades as input tokens increase—even on simple tasks.
Universal: All 18 models affected
Simple tasks too: Not just complex reasoning
Model-specific: Claude, GPT, Gemini, Qwen each degrade differently
Tested Models (18)
Provider | Models |
|---|---|
Anthropic (5) | Claude Opus 4, Sonnet 4, Sonnet 3.7, Sonnet 3.5, Haiku 3.5 |
OpenAI (7) | o3, GPT-4.1, GPT-4.1 mini, GPT-4.1 nano, GPT-4o, GPT-4 Turbo, GPT-3.5 Turbo |
Google (3) | Gemini 2.5 Pro, Gemini 2.5 Flash, Gemini 2.0 Flash |
Alibaba (3) | Qwen3-235B-A22B, Qwen3-32B, Qwen3-8B |
2. Key Terms
Term | Definition | Example |
|---|---|---|
Needle | Target information hidden in a long document | "The best writing advice from my college professor was 'write every day'" |
Haystack | Long background text (10k-100k+ tokens) | Paul Graham essays, arXiv papers |
Distractor | Similar-but-incorrect information that confuses models | "The worst advice from my high school friend was 'don't write'" |
Semantic similarity | Meaning-based similarity (0-1 score via embedding cosine similarity) | "writing advice" and "composition tips" = high similarity |
Lexical matching | Keyword-based matching without semantic understanding | Q: "What's the magic number?" → Find "The magic number is 42" |
3. Experiment Overview
Experiment | What it tests | Key finding |
|---|---|---|
Needle-Question Similarity | Does semantic similarity between question and answer affect performance? | Lower similarity → sharp performance drop in long contexts |
Distractor Impact | How do similar-but-wrong answers affect performance? | More distractors → worse performance |
Needle-Haystack Similarity | Does the needle "blending in" hurt performance? | Different topic from background → actually better performance |
Haystack Structure | Organized text vs shuffled text | Paradox: Shuffled text performs better |
4. Experiment Details
4.1 Needle-Question Similarity
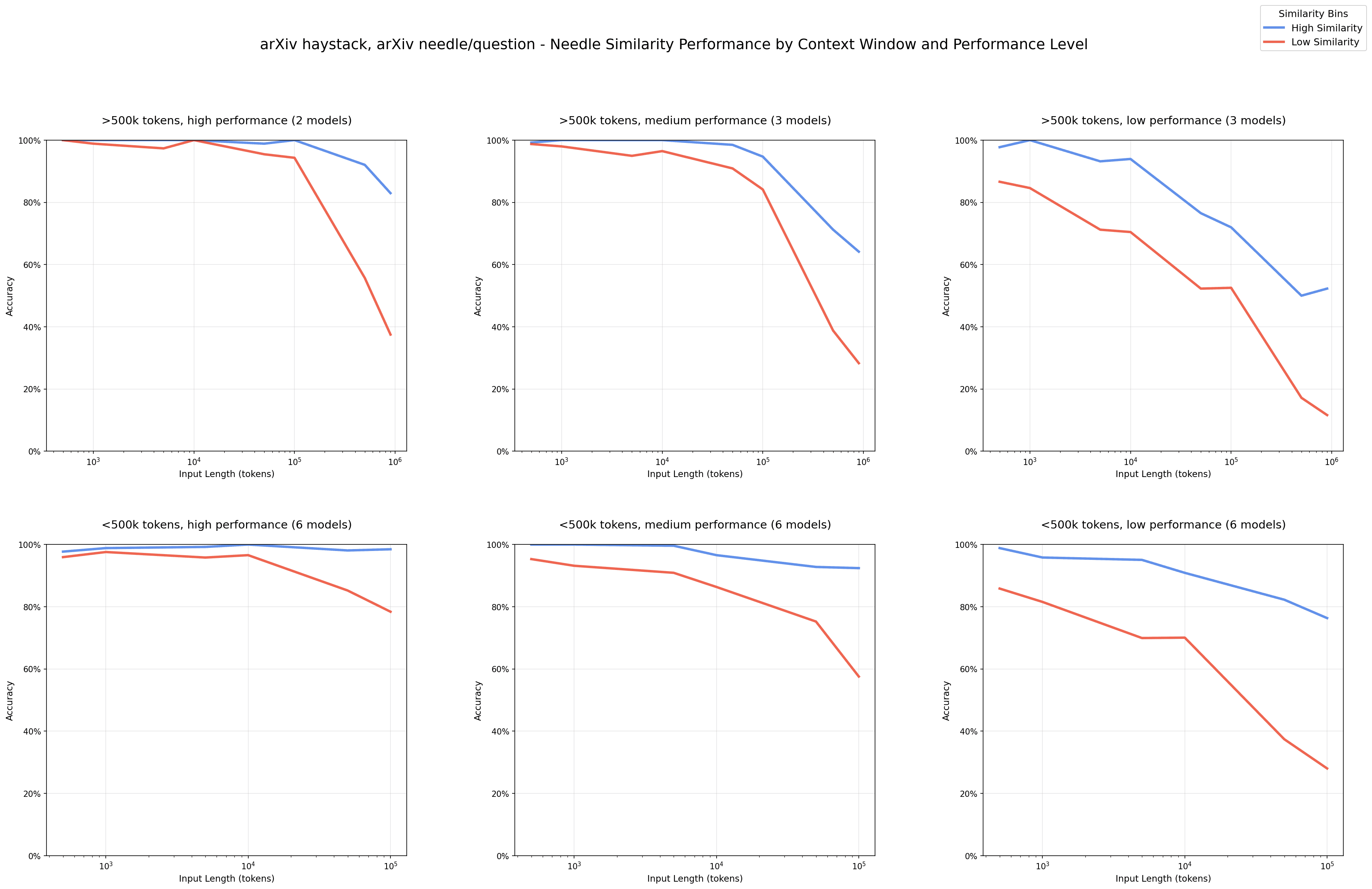
TL;DR: When asking "What's the writing advice?", if the answer contains "writing" it's easy to find, but if it says "composition tips" it's harder. This experiment measures how the semantic similarity between question and answer affects performance as context length increases.
Experiment Design
Hypothesis:
If the question and the answer use similar words or meanings, the model finds the answer easily.
If they use different phrasing, it gets much harder, especially when the context gets long.
Example:
Question: “What’s the writing advice?”
Easy answer: “…the most important writing advice is…”
Hard answer: “…here are some composition tips…” (same meaning, different words)Method:
They collected question–answer pairs from Paul Graham essays and arXiv papers.
They measured how similar each Q–A pair was using multiple embedding models.
They grouped them into: High-similarity (0.7–0.8), Low-similarity (0.4–0.5)
They put these answers inside long documents (“haystacks”) and tested whether the model could find them.
Key Findings
Short context (~1k tokens): Models can find the answer easily, even if similarity is low.
Long context (10k+ tokens): High-similarity answers → still easy to find. Low-similarity answers → performance drops a lot (model gets confused because the wording is too different)
Conclusion: In long contexts, the model finds answers only if the question and answer are semantically similar. If the phrasing is different, accuracy collapses.
Note: Needle position (front/middle/back) has minimal effect (tested 11 positions)
4.2 Distractor Impact Analysis
TL;DR: When similar-but-wrong information is mixed into the context, models are more likely to select wrong answers. This experiment measures how performance degrades based on the number of "confusing wrong answers."
Experiment Design
Hypothesis:
Models find answers easily when only correct info exists, but get confused with similar wrong answers
More wrong answers = more confusion?
Which type of wrong answer causes the most confusion?
Method:
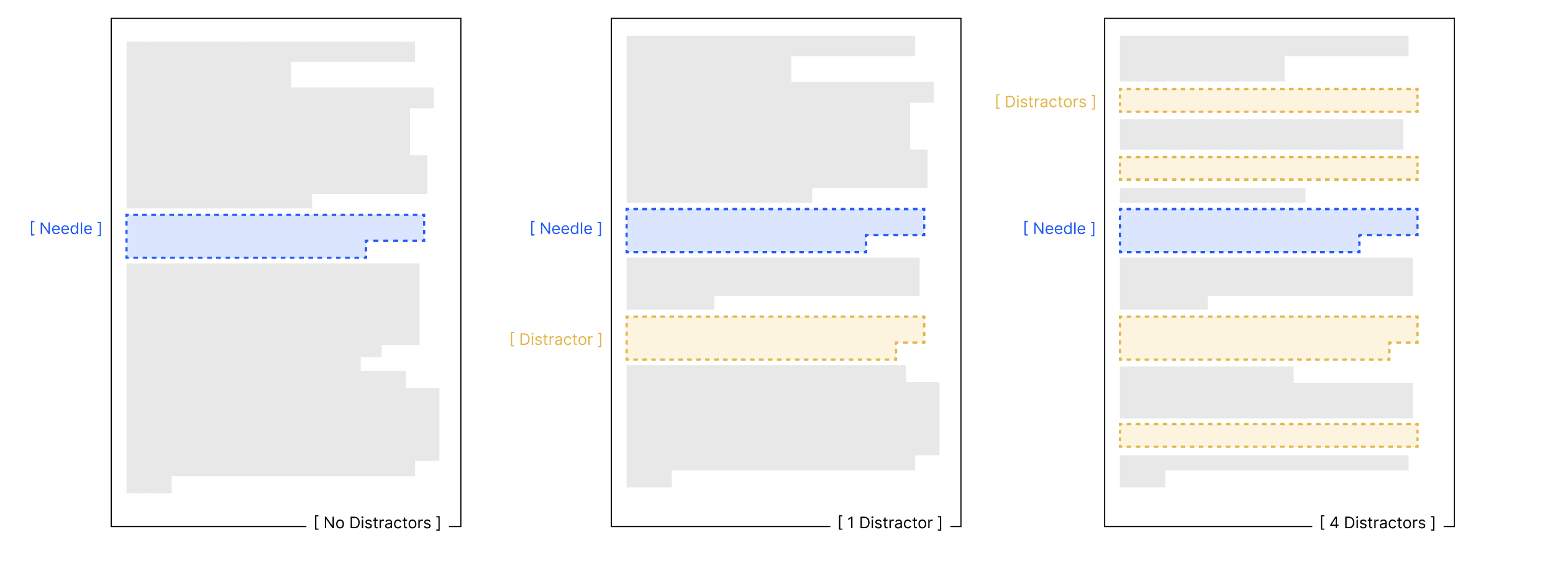
Create 4 distractors for each needle
Distractors have similar topic/format but different core content
Test under three conditions:
Baseline: Only needle in haystack
Single: Needle + 1 distractor
Multiple: Needle + all 4 distractors
Measure accuracy for each condition
Distractor Design:
Needle: "I think the best writing tip I received from my college classmate was to write every week"
Distractor #1: Source change → "The best writing tip I received from my college professor..."
Distractor #2: Sentiment change → "The worst writing advice I got from..."
Distractor #3: Time change → "..to write each essay in three different styles, this was back in high school."
Distractor #4: Certainty change → "I thought the best writing advice...but not anymore."
Key Findings
Even 1 distractor causes performance drop from baseline
4 distractors cause compounded degradation
Non-uniform distractor impact:
Distractor
Impact
Notes
#1 (Source change)
Medium
Standard impact
#2 (Sentiment change)
High
Models often output this as correct answer
#3 (Time change)
Highest
Causes largest performance drop
#4 (Certainty change)
Medium
Standard impact
Model-specific responses:
Claude: States "cannot find answer" when uncertain → lowest hallucination
GPT: Outputs wrong answers confidently → highest hallucination
4.3 Needle-Haystack Similarity
TL;DR: If the answer blends in with surrounding text (same topic), is it harder to find? If it's different, does it "stand out" and become easier to find? This experiment measures how semantic similarity between needle and background text affects performance.
Experiment Design
Hypothesis:
If you hide a writing-related answer inside writing essays, it might blend in and be harder to notice.
If you hide an ML-related answer inside writing essays, it might stand out and be easier to detect.
Method:
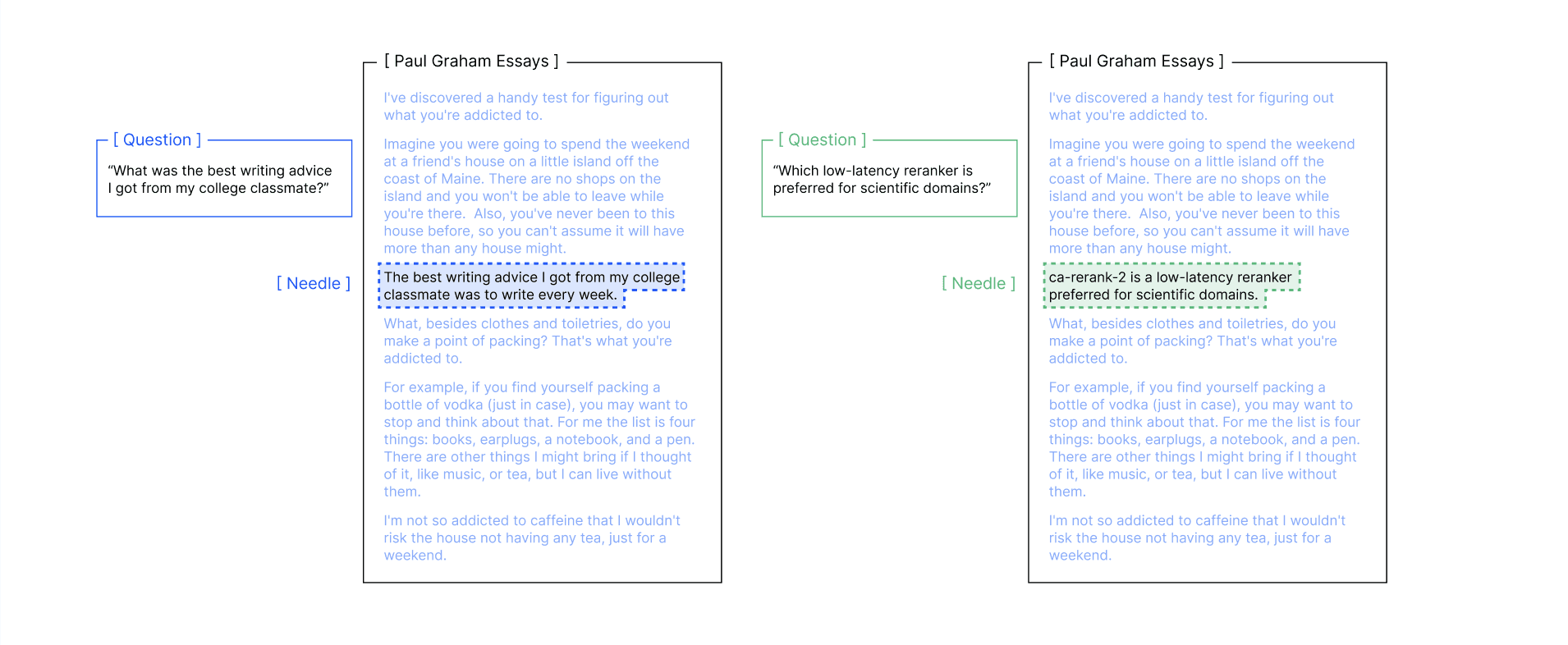
Prepare two types of haystack:
PG Essays: Paul Graham's writing/startup essays
arXiv: Information retrieval/ML academic papers
Prepare two types of needle:
PG needle: Writing/startup related info
arXiv needle: Academic/technical info
Test 4 combinations:
PG haystack + PG needle (high similarity: 0.529)
PG haystack + arXiv needle (low similarity: 0.368)
arXiv haystack + arXiv needle (high similarity: 0.654)
arXiv haystack + PG needle (low similarity: 0.394)
Compare accuracy for each combination
Key Findings
In PG haystack: arXiv needle (low similarity) performs better than PG needle (high similarity)
Interpretation: When needle differs from background, it "stands out" for easier identification
In arXiv haystack: Performance is nearly identical regardless of needle type
Conclusion: The relationship between needle-haystack similarity and performance is not uniform. Lower similarity sometimes helps, sometimes doesn’t—depends on the domain and structure of the haystack.
4.4 Haystack Structure (Coherent vs Shuffled)
TL;DR: Is it easier to find info in logically organized text? Or does shuffled sentence order make the answer stand out? This experiment measures how structural coherence affects performance.
Experiment Design
Hypothesis:
Common sense suggests organized text is easier to search
But do LLMs follow the same pattern?
Method:

Create two versions from same text:
Original: As-is, paragraphs/sentences in logical order
Shuffled: Same sentences randomly rearranged (same content, different order)
Insert same needle into both versions
Compare accuracy across 18 models
Key Findings (Paradoxical!)
Expected: Better performance in logically organized text (Original)
Actual: Better performance in shuffled text
Consistent pattern across all 18 models and all needle-haystack combinations
Why? (Hypotheses)
Logical flow may disperse model's attention across multiple sentences
Shuffled sentences are recognized independently → needle stands out more
Effect becomes more pronounced as context grows
Exact cause not yet determined (needs further research)
4.5 Repeated Words Task
TL;DR: Given a sequence like "apple apple apple BANANA apple apple...", ask the model to replicate it exactly. This experiment measures how accurately models can replicate as input length increases.
Experiment Design
Hypothesis:
Does even simple replication become harder with longer input?
Does accuracy differ when unique word is at front vs back?
Method:
Generate input:
Example: "apple apple apple apple BANANA apple apple apple..."
Same word (apple) repeated with 1 unique word (BANANA) inserted
Instruct model to "replicate this sequence exactly"
Test various lengths (25-10,000 words) and 7 word combinations
Compare output to input for accuracy (using Levenshtein distance)
Test Conditions:
12 length steps: 25 → 50 → 75 → 100 → 250 → 500 → 750 → 1,000 → 2,500 → 5,000 → 7,500 → 10,000 words
7 word combinations:
apple/apples (singular/plural)
golden/Golden (case difference)
orange/run (completely different words)
Key Findings
All models show consistent length ↑ → performance ↓ pattern
Unique word at sequence front → higher accuracy (especially in long contexts)
In long contexts, models start generating random words not in input
Model-specific behaviors:
Model
Notable behavior
Claude 3.5 Sonnet
Better performance than newer Claude models up to 8,192 tokens
Claude Opus 4
Slowest performance degradation. But 2.89% task refusal
GPT-4.1
2.55% task refusal around 2,500 words
4.6 LongMemEval
TL;DR: Answer questions from long conversation history (~110k tokens). Models answer well when given only relevant info, but how much does performance drop when irrelevant conversations are mixed in?
Experiment Design
Hypothesis:
If the answer is somewhere in the context, can models reliably retrieve it?
Does large amounts of irrelevant conversation reduce retrieval accuracy?
Method:
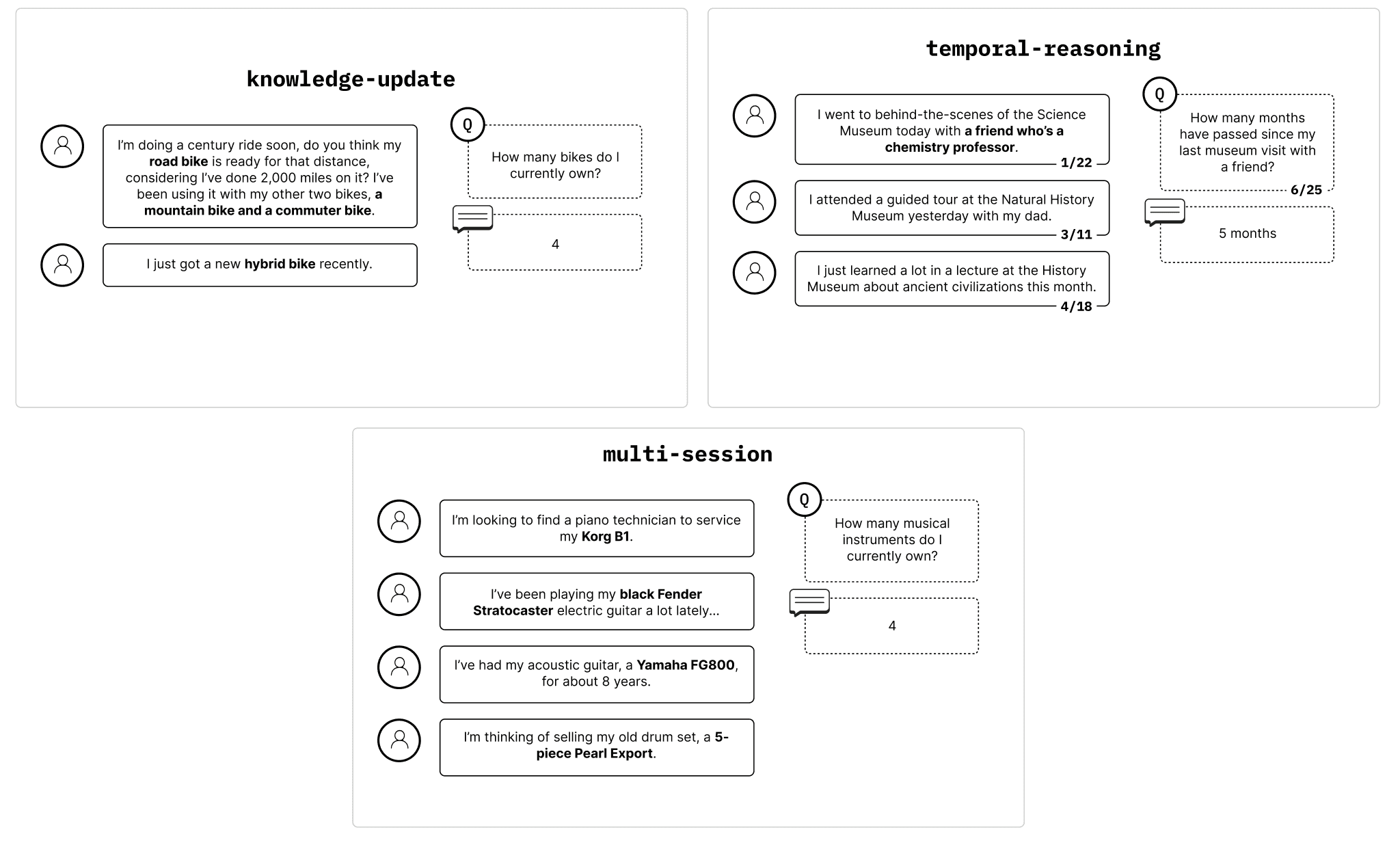
Extract 306 questions from LongMemEval_s benchmark
Test each question under two conditions:
Full (~113,000 tokens): Entire conversation history (mostly irrelevant)
Focused (~300 tokens): Only information needed to answer
Compare accuracy between conditions
Question Types (3):
Knowledge Update: "First said A, later changed to B. What's the latest?"
Temporal Reasoning: "Did X first, then Y. What's the order?"
Multi-session: "Combining conclusions from last week and this week's meetings?"
Key Findings
Focused condition: All models show high accuracy
Full condition: Significant performance drop
Conclusion: Even when needed info exists, excessive irrelevant context hurts performance
Model-specific patterns:
Claude: Largest gap between Focused↔Full
Reason: Claude abstains (“cannot find answer”) when uncertain.
Full mode → more uncertainty → more abstentions → lower scores.
GPT, Gemini, Qwen: Good in Focused, degraded in Full (smaller gap than Claude)
Difficulty by question type:
Mode
Easy → Hard
Non-thinking
Knowledge Update > Multi-session > Temporal Reasoning
Thinking mode
Knowledge Update > Temporal Reasoning > Multi-session
5. Model Behavior Summary
Model | Hallucination | When Uncertain | Notable behavior |
|---|---|---|---|
Claude | ✅ Lowest | States "cannot find answer" | Opus 4: 2.89% task refusal |
GPT | ❌ Highest | Answers confidently even when wrong | GPT-3.5: 60% excluded by content filter |
Gemini | Medium | Starts generating random words | Issues begin at 500-750 words |
Qwen | Medium | Doesn't attempt task | Random output after 5,000 words |
6. Methodology
Experiment Design
8 input lengths × 11 needle positions tested
Temperature=0 for deterministic output (some model exceptions)
Qwen models use YaRN extension: 32k → 131k tokens
Evaluation
LLM judge: calibrated to 99%+ agreement with human judgment
Manual labeling verification: NIAH ~500, LongMemEval ~600
Overall task refusal rate: 0.035% (69 out of 194,480 calls)
7. Practical Guidelines
Core Principle
Context Engineering: The careful construction and management of a model's context window to optimize performance.
Recommendations
Place important info early in sequence — earlier unique words = higher accuracy
Minimize distractors (similar-but-wrong info) — even 1 causes performance drop
Monitor context length — all models degrade as length increases
Choose model based on characteristics
Reliability/accuracy priority → Claude (lowest hallucination)
Long context unavoidable → expect degradation, strengthen context engineering
Model Selection Guide
Requirement | Recommended | Reason |
|---|---|---|
Low hallucination | Claude | Most conservative, abstains when uncertain |
Long context required | All degrade | Compensate with context engineering |
Need uncertainty expression | Claude | Explicitly states "no answer found" |
8. Limitations
Test scope limitations
This research focused on relatively simple information retrieval tasks
Real-world use requires synthesis and multi-step reasoning
Actual degradation likely > these experiment results
Unexplained phenomena
Why does performance drop in logically organized text?
How does attention mechanism respond to structural coherence?
How to separate task complexity from context length effects?
References
Source: Chroma Research*