Basics of Context Engineering: Session and Memory
Dec 2, 2025
Insights are derived from Google’s whitepaper on Context Engineering, and Manus’s blog on Context Engineering for AI Agents
Key Concepts
Context engineering: process of dynamically assembling and managing info within an LLM’s context window to enable stateful agents.
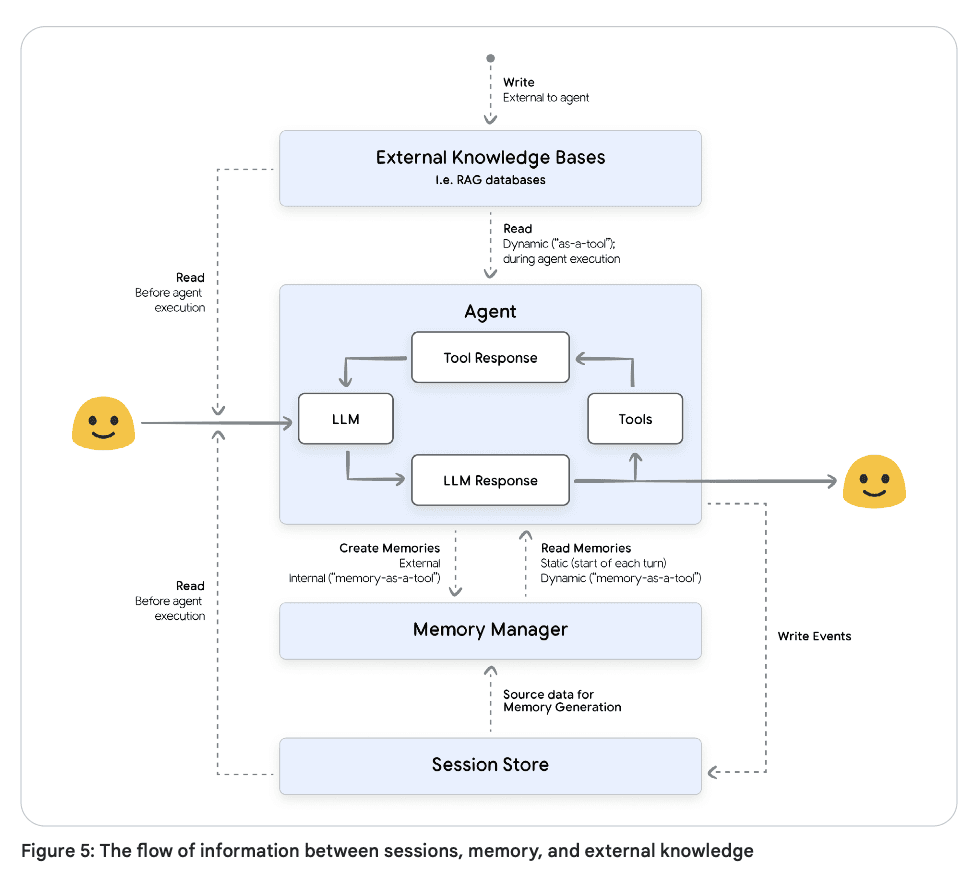
Sessions: container for an entire conversation within agent, holding the chronological history of the dialogue
Memory: long-term persistence by capturing and consolidating key info across multiple sessions
Main challenge of building context-aware agent
managing ever-growing conversation history: as context grows, cost and latency increases
context rot: ability to pay attention to important info diminishes as context grows
→ Solution: context engineering aims to solve this by dynamically mutating the history, through methods of 1) summarization, 2) selective pruining, 3) other compaction techniques
Sessions
session: self-contained record tied to specific user
two components: events and state
events: user input, agent response, tool call, tool output
state: structured working memory or sratchpad, holding temporary data (ex: outputs of tool calling)
session history is different from context. Session is the persistent log of all interactions and the permanent transcript of the entire conversation. Context is the carefully selected information payload sent to the LLM.
Managing session history for multi-agent systems
Shared, unified history where all agents contribute to single log (ex. git main branch)
all agents read from and write all events to same conversation history
events appended to one central log in chronological order
best for tightly coupled, collaborative tasks requiring single source of truth
also best for multi-step problem solving process where one agent’s output is the direct input of the next
Separate, individual histories where each agent maintains its own perspective (ex. git branch)
each agent maintains its own private conversation history
all internal processes of thoughts, tool use, reasoning stepa are kept within each agent and not visible to others
this interaction is implemented by building Agent-as-a-tool or Agent-to-Agent (A2A) protocol
Problems with A2A communication
fails to address core problem of sharing rich, contextual state
as each agent’s conversation history is encoded in its own framework, a A2A message containing session events requies a translation layer
to build abstracted shared knowledge into a framework-agnostic layer, we build Memory
a memory layer is designed to hold processed, canonical information, serving as a universal common data layer
Managing long context sessions
Compaction strategies: how to know what content to throw out of a session without losing valuable info?
Keep the last N turns: only keeps most recent N turns of conversation and discards everything older
depends on which value is needed for the specific app you’re trying to build
if the agent’s task is confined to a very particular task with expected outcomes, info that needs to be retained becomes extremely clear. in this case, semantic compaction would be more reasonable
Token-based Truncation: includes as many messages as possible within predefined token limit
Recursive Summarization: Older parts of conversation are replaced by AI generated summary
Other compaction strategies (from Manus)
based on Context Engineering for AI Agents: Lessons from Building Manus, Peak Ji recommends using the “file system” as context
overly agressive compression leads to information loss
you can’t reliably predict which observation might become critical ten steps later
treats the file system as ultimate context in Manus
meaning, their compression strategies are always designed to be restorable
ex. content of web page can be dropped from context as longa s the URL is preserved
document’s context can be omitted if its path remains in the sandbox
allows Manus to shrink context length without permanently losing info
Manipulate attention through recitation
constantly rewrite the todo list, to recite the objectives into the end of the context
this pushes the global plan into the model’s recent attention span, avoiding “lost-in-the-middle” issues
Keep wrong stuff in
do not erase hallucinations or external tool call failures
erasing failure removes evidence, and without evidence, model can’t adapt
leave the wrong turns in the context. wen model sees failed action, it implicitly updates its internal beliefs
Don’t get few-shotted
few-shot prompting can backfire, because they imitate the pattern of behavior in context.
if context is full of similar past action-observation pairs, the model will tend to follow that pattern even when it’s no longer optimal
increase diversity. controlled randomness helps break patter.
Also need to consider “when” compaction is necessary
count-based triggers: token size or count threshold
time-based triggers: if user stops interacting for set period, system runs compaction job
event-based triggers: semantic/task completion system. triggers when specific task, sub-goal or topic is concluded
Memory
memory: snapshot of extracted, meaningful info from conversation
memory manager provides foundation for multi-agent operability
Components to memory
The user: providing raw source data for memories
The agent (Developer logic): congifures how to decide what and when to remember
simple architecture: implement logic so that memory is always retrieved and always triggered to be generated
advnaced architecture: implement memory-as-a-tool, where agent (LLM) decided when memory should be retrieved or generated
Agent Framework (ADK, Langraph): provides structure and tools for memory interaction. But doesn’t manage long-term storage itself
Session stoarge (Agent Engine Sessions, Spanner, Redis): stores turn-by-turn conversation of the Session
Memory Manager (Agent Engine Memory Bank, Mem0, Zep): handles storage, retrieval, compaction of memories
extraction
consolidation
storage
retrieval
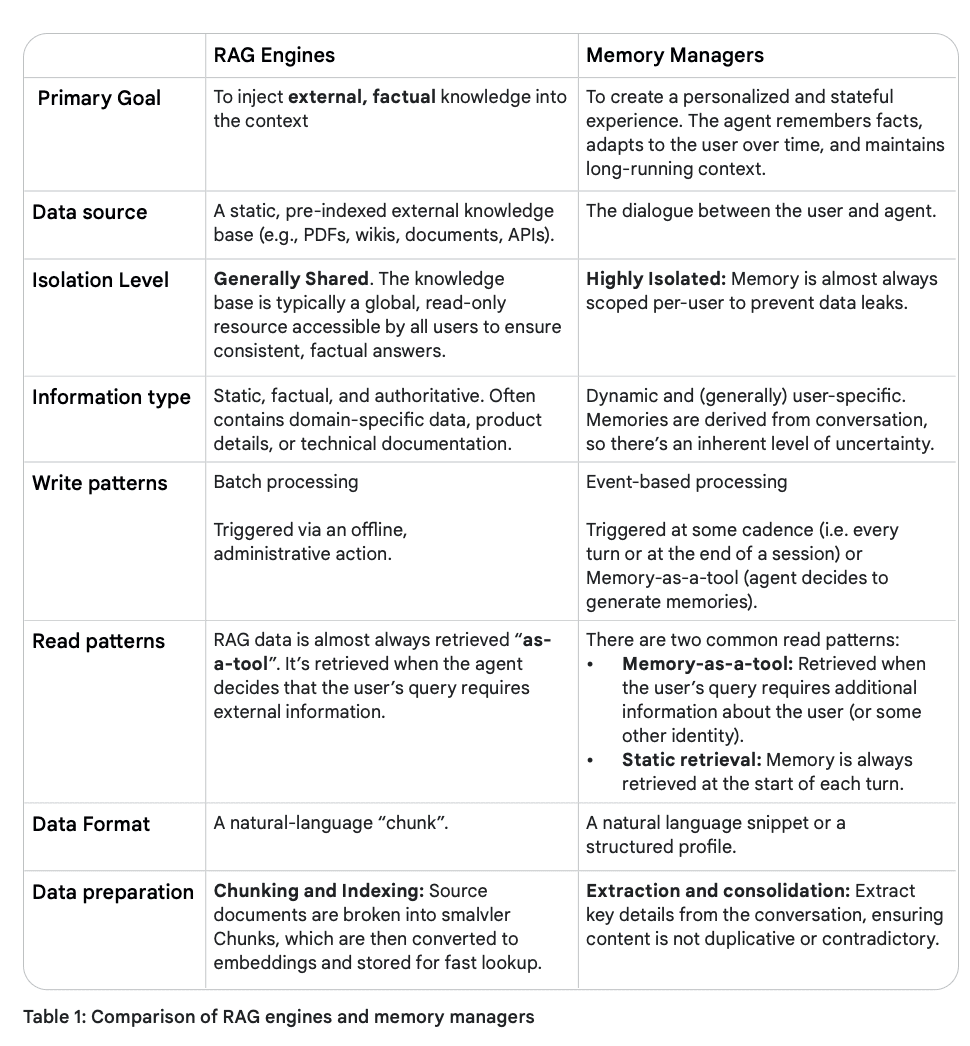
Comparison of RAG and memory managers
Storage architectures
vector databases: help find memories that are conceptually similar to the query
retrieving unstructured, natural language memories where context and meaning are key
knowledge graphs: store memories as a network of entities and their relationships
find direct and indirect connections
ideal for structured, relational queries and understanding complex connections within data
Memory Generation: Extraction and Consolidation
memory manager uses an LLM to intelligently decide when to add, update, or merge memories (Agent Engine Memory Bank, Mem0, Zep)
Four stages:
Ingestion: when client provides a source of raw data
Extractoin & filtering: memory manger uses LLM to extract meaningful content from source data. only captures info that fits a predefined topic definition.
Consolidatoin: most sophisticated stage, where manager handles conflict resolution and deduplication
performs “self-editing” process, using LLM to compare new extracted info with existing memories
it can decide to 1) merge, 2) delete, 3) create
Storage: new/updated memory is persisted to a durable storage layer
Memory extraction
Key: What info in this conversation is meaningful enough to become a memory?
this is obviously not universal and differs based on app/agent’s purpose and use case
memory manager’s LLM decides what to extract based on carefully constructed set of programmatic guardrails and instructions, usually embedded in a complex system prompt
LLM is given predefined JSON schema or template with structured output
few shot prompting also shows LLM what info to extract
Memory Consolidation
Key: How to integrate new info into a coherent, accurate, evolving knowledge base
Information duplication: should not create two redundant memories
conflicting information: can’t contain contradictory facts from user
information evolution: simple fact can become more nuanced.
memory relevance decay: not all memories remain useful forever. agent should proactively prune old, stale, low-confidence memories. forgetting can be triggered via TTL
Core task is to analyze existing memories and new information
update, create, delete/invalidated based on comparison
Memory Provenance
For agent to make reliable decisions and for a memory manager to effectively consolidate memories, they must have a provenance - a detailed record of the memory’s origin and history.
some issues: a single memory might be a blend of multiple data sources, and a single source might be segmented into multiple memories
To address trustworthiness, must track key details for each source:
this dictates weight each source has during memory consolidation
also informs how much the agent should rely on that memory during inference
Source types:
Bootstrapped data: initialize user’s memories to address cold-start problem
user input: data provided explicitly
tool output: data from tool call. generating memories from tool output is generally discouraged, as they then to be brittle and stale - better for short-term caching
Triggering memory generation
Session completion
turn cadence: after specific number of turns
real-time: generate after every single turn
explicit command: upon user’s direct command
Need to consider costs & latency for frequent generation.
Memory-as-a-tool
more sophisticated approach is to allow agent to decide for itself when to create memory
tool definition should define what types of info should be considered meaningful
agent can then analyze conversation and auto decide to call this tool
Inference with memories
final step is to strategically place them into model’s context window
placement of memory can significantly influence LLM’s reasoning and affect costs, and the quality of the final answer
1. Memories in system instructions
gives memories high authority, cleanly separates context from dialogue, ideal for “global” info like user profile
BUT risk of over-influence, where agent might try to relate every topic back to memories
Several constraints:
requires agent framework to support dynamic construction of system prompt before each LLM call
patter is incompatible with memory-as-a-tool as the system prompt must be finalized bofre the LLM can deicde to call a memory retrieval tool
poorly handles non-textual memories
2. Memories in conversation history
place before full history or right before latest user query
Constraints:
noisy, increases token costs and confuses the model if retrieved memories are irrelavant
primary risk is dialogue injection, where model might treat memory as something that was actually said in conversation
memory should be written in first-person point of view
Testing and Eval
Memory generation quality:
precision: Of all the memories the agent created, what percentage are accurate and relevant?
recall: of all the relevant facts it should have remembered from the soruce, what percentage did it capture?
f1-score: combination of precision and recall
Retrieval performance
recall@K: When a memory is needed, is the correct one found within the top 'K' retrieved results?
Latency: must execute within latency budget
End-to-end task success