Agentic Context Engineering
Dec 8, 2025
[Part 1] Evolving Contexts & Self-Evolving Memory: How LLMs Learn From Experience
LLMs are shifting from static chatbots into dynamic agents: systems that can reason, act, observe results, and improve over time. Two lines of research push this frontier forward:
EvoMemory: building self-evolving memory systems that learn strategies directly at test-time.
Agentic Context Engineering (ACE): building self-evolving contexts that grow through structured updates.
Both break from the old paradigm of prompting and instead propose mechanisms that let agents learn continuously, without any retraining, weights, or architecture changes.
This article breaks down the core ideas from both papers.
Why We Need Evolving Knowledge Systems
Stateless LLM agents today operate mostly like this:
Get a prompt.
Solve the task.
Forget almost everything.
This leads to:
Context collapse: when repeated rewriting compresses and destroys essential details
Stagnant performance: the agent cannot accumulate tactics or lessons
No strategic reuse: the model performs each task as if it’s the first time
The two new frameworks, ACE and EvoMemory, fight these issues by enabling accumulative knowledge growth.
ACE (Agentic Context Engineering)
1. Problem
Current Problem: Brevity bias and context collapse
LLM agents rely heavily on context: instructions + domain knowledge + prior learnings.
Over time, as agents try to update this context, it collapses.
important details are lost.
domain-specific strategies get overwritten.
long-term expertise never accumulates.
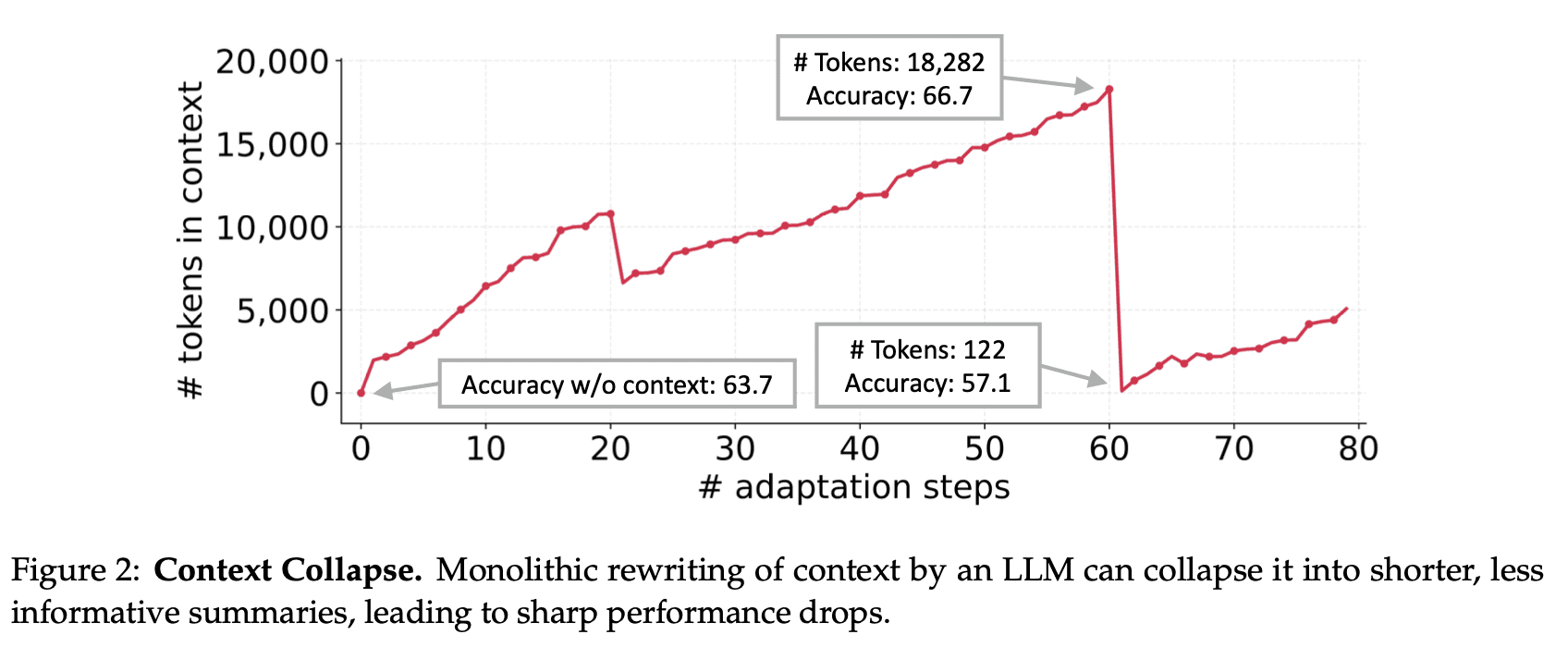
Why This Happens
Most current systems update the context by:
rewriting the entire prompt,
summarizing everything repeatedly,
regenerating the whole context block after each task.
This causes 1) over-compression, 2) loss of nuance, 3) destruction of carefully structured knowledge
The result: Agents cannot evolve. They forget as fast as they learn.
2. Limitations of Current Approaches
1. Full rewrites cause information destruction
Repeated summarization → specialized details flatten into generic summaries.
2. No structure is enforced
Contexts become long paragraphs, unordered, hard to update safely.
3. No modular process for updating knowledge
Most systems let the agent dump insights into the prompt with no filtering, no quality control, no schema.
4. No mechanism to prevent “context drift”
Unstructured updates → the context becomes inconsistent and contradictory
The ACE team specifically identifies that the lack of structure + full rewrites is what causes collapse.
3. What ACE Proposes
A modular workflow of generation, reflection, and curation, while adding structured, incremental updates guided by a grow-and-refine principle.
A context that evolves through small, non-destructive updates: “delta updates”
Instead of rewriting the entire context, ACE:
preserves the existing content,
applies only small, targeted changes,
ensures all content stays structured and human-readable.
The context becomes a living playbook.
4. How ACE Solves the Problem
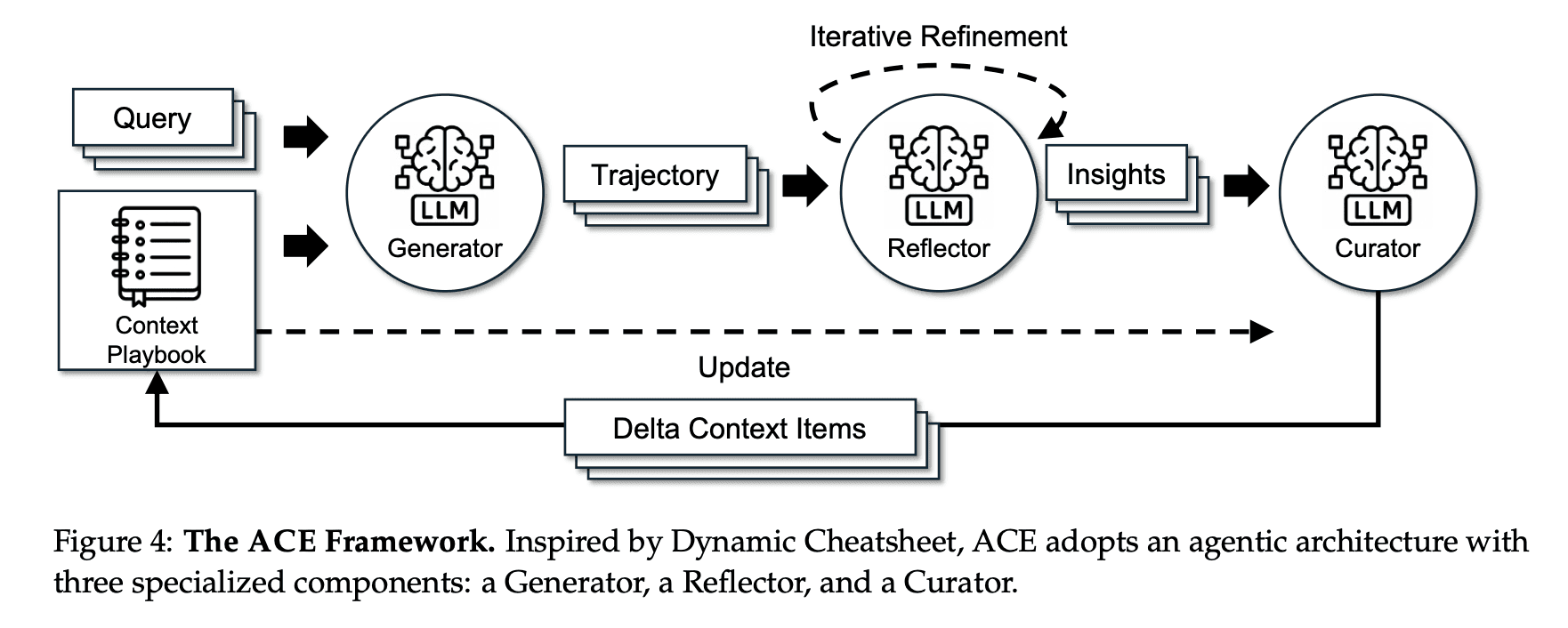
Instead of condensing knowledge into summaires or static instructions, ACE treats contexts as evolving playbooks that continuously accumulates, refines, organizes strategies over time.
ACE builds a three-module workflow that cleanly separates:
Experience generation: the Generator, which produces reasoning trajectories
Reflection & critique: the Reflector, distilling concrete insights from successes and errors
Context updating (delta edits): the Curator, integrating these insights into structured context updates
This introduces three innovations:
Reflector that separates evaluation and insight extraction from curation
incremental delta updates that replace costly monolithic rewrites with localized edits
grow-and-refine mechanism that balances steady context expansion with redundancy control
Again, here is how the workflow happens:
Generator produces reasoning trajectories for new queries
Reflector critiques these traces to extract lessons
Curator synthesizes these lessons into compact delta entires
Delta entires are merged deterministically into existing context by lightweight, non-llm logic
Mechanism 1: Incremental Delta Updates
Everything the agent learns is stored in:
bullet points: consisted of metadata (unique identifier and counters tracking how often it was marked helpful or harmful) and content (small unit such as reusable strategy, domain concept, common failure mode)
Generator highlights which bullets were useful/harmful, guiding the Reflector
This enables three properties:
Localization: only relevant bullets are updated
Fine-grained retrieval: Generator can focus on most pertinent knowledge
Incremental adaptation: efficient merging, pruning, de-duplication during inference
ACE produces compact delta contexts: small sets of candidate bullets distilled by Relfector and integrated by Curator.
Mechanism 2: Grow-and-Refine
Ensures contexts remain compact and relevant:
bullets with new identifiers are appended
existing bullets are updated
de-duplication step prunes redundancy by comparing bullets via semantic embeddings
5. What ACE’s Full System Looks Like
From the extracted text, ACE’s system always produces:
✔ Bullet-style “playbook” context
✔ Delta updates instead of rewrites
✔ A modular pipeline that evolves this playbook
Think of it as:
A knowledge base that grows knowledge like Git, through patches, not rewrites.
6. How They Tested ACE
The paper evaluates ACE by:
Plugging ACE into existing LLM agent tasks
Measuring performance over multi-step missions
Comparing it to:
Static prompts
Full-rewrite self-improving prompts
Other reflection-based methods
ACE was tested on:
AppWorld (agent benchmark)
Domain-specific reasoning tasks (e.g., finance)
They also tested:
ability to accumulate expertise
robustness over long sequences
resistance to context collapse
7. Results
1. ACE enables powerful self-improving agents
ACE improves AppWorld accuracy by up to +17.1% simply by refining the agent’s input context.
It uses execution feedback only (no ground-truth labels needed).
A smaller open-source model with ACE matches or surpasses the top proprietary system on the AppWorld leaderboard.
Takeaway:
ACE can turn a weaker model into a top-tier agent purely through better context engineering.
2. Large Gains in Specialized Domains
On financial reasoning benchmarks (FiNER and Formula):
ACE improves accuracy by +8.6% on average over strong prompt-optimization baselines.
ACE constructs comprehensive domain playbooks capturing financial concepts, XBRL rules, and reusable strategies.
Takeaway:
ACE is especially strong when tasks require deep domain expertise, not just general reasoning.
3. ACE’s design choices actually matter
Ablations show that components like:
the Reflector (which extracts lessons), and
multi-epoch refinement (revisiting data multiple times)
each contribute meaningfully to the final performance.
Takeaway:
The system works because of its structure.
4. ACE is dramatically cheaper and faster
ACE reduces adaptation cost across the board:
82.3% lower latency and 75.1% fewer rollouts than GEPA (AppWorld, offline)
91.5% lower adaptation latency and 83.6% lower token cost than Dynamic Cheatsheet (FiNER, online)
Takeaway:
ACE scales cheaply and is practical for real deployments.